
Namaste.
Ich habe recht viel mit Natural Language Processing (NLP) gearbeitet. Das Thema ist grad in aller Munde. Jeder da draußen will irgendwie Chatbots einsetzen um irgendetwas zu verbessern. Das ist wichtig. Das ist legitim. Wiederum andere wollen gerne lange Texte zusammenfassen und sich so vorm Information Overload retten. Auch das ist sehr nützlich. Und andere würde gerne mit Künstlichen Intelligenzen zwischen den Zeilen ihrer historischen Dokumente lesen. Da gibt es viel zu holen.
Deep Learning mit natürlicher Sprache zu betreiben ist recht greifbar. Greifbar aber nicht trivial. Es gibt da ein paar Lernschwellen zu überwinden. Damit werden wir uns jetzt beschäftigen.
Natural Language Processing… Wie macht man Sprache Neuronalen Netzen verständlich?
Natural Language Processing ist eine Mischwissenschaft. Das Feld besteht anteilig aus Computer Linguistics, Computer Science und Artificial Intelligence. Also der Wissenschaft der algorithmischen Verarbeitung von Sprache, der Wissenschaft von der Verarbeitung von Daten und der Wissenschaft vom künstlichen, intelligenten Verhalten. Natural Language Processing ist sehr nah an der Man-Machine-Interaction dran. Menschen und Maschinen verstehen sich zwar gut, aber noch nicht prächtig. Hier wird noch fleißig geforscht.
Deep Learning in Bezug auf Sprache hat sehr viel mit großen Textkorpora zu tun. Wir erinnern uns, dass Neural Networks meistens recht hungrig auf Daten sind. Ein solcher Korpus ist in erster Linie nicht mehr als eine große Menge an Texten. Die Größe ist use-case-spezifisch. Die Qualität spielt auch eine Rolle. Auch hier waren viele Leute schon lange fleißig. Ob Dialoge aus Hollywood-Filmen oder die gesamten Werke großer Dichter… Es stehen viele solcher Sammlungen frei zur Verfügung. Doch wie bereitet man Texte auf, damit Neural Networks mit ihnen arbeiten können? Oder genauer, wie kann man Wörter und Sätze in Neural Networks einspeisen? Ich sage ja gerne, dass die Netze eigentlich nicht viel mehr machen, als aus Zahlenreihen andere Zahlenreihen zu generieren.
Texte müssen kodiert werden. Ohne Kodierung kein Deep Learning.
Neural Networks haben eine kleine Einschränkung. Die Eingaben und Ausgaben haben immer eine feste Länge. Die Breite der Eingabe- und Ausgabeschichten gehören zu den sogenannten Hyperparametern und sind für jedes Model fest. Braucht man breitere Eingaben, so muss eine neue Instanz des Models her.
Allgemein gibt es viele Möglichkeiten, Wörter zu kodieren. Der Standardansatz einfach Zeichenketten zu benutzen, hilft leider wenig, weil die Länge beliebig sein kann. Der Duden nennt etwa „Arbeiterunfallversicherungsgesetz“ als eines der längsten Wörter der deutschen Sprache. Das sind satte 33 Zeichen. Das häufigste deutsche Wort „der“ hingegen hat nur drei Zeichen. Ein Netz, dass mit Wörtern dieser Längen umgehen kann, müsste also 33 Eingänge haben. Für die meisten Wörter wäre das Verschwendung. Bei unserem kleinen Wort „der“ wären 30 Zeichen unbenutzt.

Es gibt mehrere Kodierungsarten fester Länge. Einfach und intuitiv sind die One-Hot-Vectors. Diese sind so lang wie der Wortschatz Wörter hat. Die Stelle an der das Wort in diesem steht, der Index, ist im One-Hot-Vector mit einer Eins markiert. Der Rest sind Nullen. Klingt einfach. Klingt intuitiv. Hat leider zwei massive Nachteile. Erstens sind die Vektoren sehr lang. Besonders wenn das Vokabular groß ist. Wer sich auf Deutsch ohne Schwierigkeiten verständigen möchte, braucht einen Wortschatz von 50000 Wörtern. Das gibt richtig lange Vektoren. Aber das ist nicht alles… One-Hot-Vectors tragen keine Semantik. Es gibt keinen Zusammenhang zwischen den Wörtern. Dass „Berlin“ etwas mit „Deutschland“ zu tun hat ist nicht gespeichert.
Word-Embeddings to the rescue!
Ein schlauer Mensch namens Harris hat 1951 den Begriff Distributional Hypothesis – oder auf deutsch Distributionelle Hypothese – geprägt. Hier versteckt sich eine ganz einfache Tatsache… Wörter die im selben Kontext daheim sind, stehen im Korpus nah aneinander. So kann man über einfache Abstandsberechnungen in großen Texten feststellen, in welchem Zusammenhang einzelne Wörter stehen.

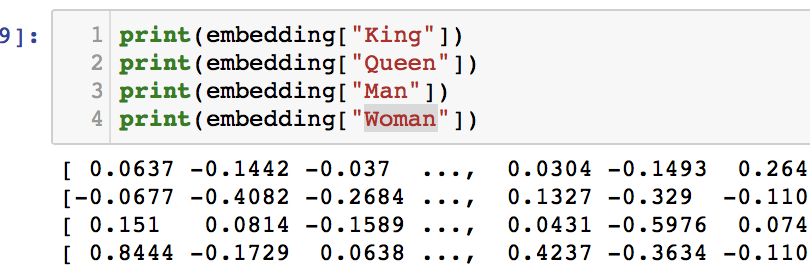
Ich benutze gerne das Beispiel zu Hofe. Es ist einfach und einprägsam. Es macht einfach deutlich, was Word-Embeddings sind und was man damit anstellen kann. Ein Word-Embedding liefert zu jedem Wort einen Word-Vector. Dieser hat eine feste Länge und besteht aus Fließkommazahlen. In diesen Zahlen ist die ganze Semantik des Wortes verborgen. Jetzt kommt die Mathematik… Was passiert wenn man vom Vektor von „König“ den Vektor von „Mann“ abzieht und den Vektor für „Frau“ aufaddiert? Richtig. Der Vektor für „Königin“!
Ähnlich zum Geschlecht ist es auch mit der Zeit. Theoretisch kann man einen ganzen Text, der in der Vergangenheit geschrieben ist, in einen verwandeln, der in der Zukunft geschrieben ist. Man kann sich Synonyme und Antonyme raussuchen lassen. Und man kann sich die Hauptstädte von Ländern ausrechnen, denn schließlich stehen Land und Hauptstadt recht nah beieinander.
Um das beste Word-Embedding ist ein Wettbewerb ausgebrochen.
Nun, Word-Embeddings gibt es schon eine Weile. Momentan gibt es einen halbernsten Wettbewerb um das beste und genaueste. Hier ist eine kleine Übersicht der gängigsten Einbettungen:
- GloVe: Von der Uni Stanford. Ist recht bekannt.
- Word2Vec: Ist von Google und basiert auf einem Neural Network mit zwei Schichten.
- FastText: Die Kollegen von Facebook waren auch fleißig und leisten einen ordentlichen Beitrag.
- Eigenwords: Das ist momentan ein heißes Eisen im Feuer der Universität von Pennsylvania.
Ich fasse zusammen.
Neural Networks kann man auf vielen Gebieten einsetzen. Alle Gebiete sind spannend. Natürliche Sprache ist spannender. Hier muss man amtlich kodieren, damit der Sinn hinter Worten und Sätzen nicht verloren geht. Word-Embeddings sind hier wunderbar geeignet. Damit macht man aus Wörtern Vektoren mit denen man sogar rechnen kann. Wenn man Natural Language Processing im Deep Learning einsetzen will, kommt man nicht an ihnen vorbei.





