
Conversational Agents sind eigentlich nur Chatbots. Im Chatbots Magazine gab es vor einer Weile den Artikel Contextual Chatbots with Tensorflow. Der Artikel ist sehr spannend. Er zeigt wie man einen Chatbot mit wenigen Zeilen Code in TensorFlow bauen kann. Na gut, eigentlich mit TF Learn. Das ist technologisch eine Schicht über TensorFlow und macht vieles einfacher. Mit TensorFlow wäre der Artikel ein wenig länger gewesen, weil TensorFlow dazu neigt, sehr lange Quelltexte zu erzeugen.
Der Artikel hat mich sehr begeistert. Jetzt will ich ihn aufgreifen und ein wenig durchleuchten. Der Inhalt ist toll und wichtig. Er ist ein gutes Beispiel für einen sehr guten Ansatz von AI. Der Ansatz ist sehr elegant – er kombiniert Deep Learning, Bag-of-Words und endliche Automaten. Trotzdem hat der Ansatz ein paar natürliche Grenzen – da kann an einigen Stellen noch nachgeschärft werden.
Ich war so frei und habe den Quelltext ein wenig aufgeräumt und das Neural Network nach Keras portiert. Er ist in meinem GitHub-Repository zu finden. Viel Spaß damit!
Worum geht es eigentlich? Die Frage soll erlaubt sein.
Ein Anwendungsfall von AI war schon immer die Verarbeitung natürlicher Sprache. Der Turing Test ist in der Wissenschaft nach wie vor legendär. Aus Film und Fernsehen kennt man diese künstlichen Entitäten mit denen man sich gut unterhalten kann. Der Streifen Ex Machina ist ein geniales Beispiel dafür.
Ich rede gerne davon, dass Deep Learning die IT gerade massiv umkrempelt. Vielerorts wird immer mehr durch AI unterstützt. Nach und nach werden alle Anwendungsfälle von Machine Learning durch Deep Learning umgesetzt. Hier passiert viel. Und warum? Weil die Sterne im Moment günstig stehen. Die Daten sind en masse da. Es gibt spannende Probleme zu den Daten. Die Algorithmen bewegen sich von der Wissenschaft in die Industrie. Die Software steht jedermann zur Verfügung. Und die Hardware zum Trainieren sowieso.
Natürliche Sprachverarbeitung ist ein Hauptanwendungsfall von Deep Learning. Conversational Agents (sometimes known as: Chatbots) sind nur einer davon. Daneben stehen unter anderem automatische Übersetzer und textzusammenfassende Systeme. Sprache zu verarbeiten ist im Gegensatz zum Umgang mit zum Beispiel Bildern oder Sounds um Längen anspruchsvoller. Das hat im Wesentlichen mit der Komplexität der menschlichen Sprache zu tun.
Bag-of-Words – Für das kleine Vokabular von einfachen Conversational Agents.
Im Natural Language Processing gibt es viele Methoden der Sprachkodierung. Über eine andere hatte ich letztens geschrieben – Word Embeddings. Mit dieser Methode kann man Wörter in Zahlenvektoren umwandeln. Und damit kann man wiederum rechnen. Über Word Embeddings kodiert man Texte fürs Deep Learning und bewahrt dabei die Semantik zu einem großen Teil. Das ist die Speerspitze der Kodierung.
Bag-of-Words ist ein verwandter Ansatz. Dieser ist vergleichsweise weniger komplex. Auch hier werden Sätze beziehungsweise ganze Texte kodiert. Wichtig ist diese Annahme: Die Reihenfolge und das mehrfache Vorkommen von Wörtern sind nicht maximal wichtig. Man arbeitet hier mit mathematischen Mengen, in denen nichts doppelt vorkommt. Bei der Bag-of-Words-Methode wird bewusst in Kauf genommen, dass grammatikalische Finessen zum Teil verloren gehen. Überraschenderweise kann man so trotzdem robuste Systeme bauen. Sprache ist magisch. Natural Language Processing sowieso.
Bag-of-Words sind algorithmisch einfacher als Word Embeddings. Was braucht man für die Bag-of-Words? Als erstes wie immer einen Textkorpus. Also die gesammelten Werke von Johann Wolfgang von Goethe, die Untertitel aller John-Wayne-Filme oder die gesamte Wikipedia. Jedes Korpus hat ein Vokabular. Also die Menge aller verschiedenen Wörter im Korpus. Die Größe der Bag-of-Words ist abhängig von der Größe dieses Vokabulars. Das ist eine performance-kritische Kennzahl.
Neben dem Vokabular werden als zweites Sätze benötigt die man kodieren möchte. Kodierung geschieht immer relativ zum Vokabular. Und hier wird es ganz einfach. Das Bag-of-Words eines beliebigen Satzes ist zunächst ein Vektor. Dieser ist so lang wie das Vokabular Elemente hat. Jede Stelle in diesem Vektor steht für ein Wort aus dem Vokabular. Ist dieses Wort aus dem Vokabular in dem zu kodierenden Satz enthalten ist die entsprechende Stelle im Vektor 1, sonst 0. Ganz einfach.
Bag-of-Words – Mal programmiert.
Die Implementierung umfasst wenige Code-Zeilen. Als Korpus habe ich den Anfang vom berühmten Faust-Monolog genommen. Das Korpus ist bewusst sehr kurz gehalten. Den Satz, den ich kodieren möchte, nehme ich ebenfalls aus dem Faust. Hier ist die Implementierung:
import nltk
import numpy as np
corpus = """Habe nun, ach! Philosophie,
Juristerei und Medizin,
Und leider auch Theologie
Durchaus studiert, mit heißem Bemühn.
Da steh ich nun, ich armer Tor!
Und bin so klug als wie zuvor;
Heiße Magister, heiße Doktor gar
Und ziehe schon an die zehen Jahr
Herauf, herab und quer und krumm
Meine Schüler an der Nase herum –
Und sehe, daß wir nichts wissen können!
Das will mir schier das Herz verbrennen."""
sentence = """Zwar bin ich gescheiter als all die Laffen,
Doktoren, Magister, Schreiber und Pfaffen;
Mich plagen keine Skrupel noch Zweifel,
Fürchte mich weder vor Hölle noch Teufel –
Dafür ist mir auch alle Freud entrissen,
Bilde mir nicht ein, was Rechts zu wissen,
Bilde mir nicht ein, ich könnte was lehren,
Die Menschen zu bessern und zu bekehren."""
def main():
vocabulary = get_vocabulary_from_corpus(corpus)
print("Vocabulary length:", len(vocabulary))
print("Vocabulary:", vocabulary)
bag_of_words = get_bag_of_words(sentence, vocabulary)
print("Bag-of-words:", bag_of_words)
def get_vocabulary_from_corpus(corpus):
tokens = get_tokens_from_text(corpus)
vocabulary = sorted(list(set(tokens)))
return np.array(vocabulary)
def get_bag_of_words(sentence, vocabulary):
tokens = get_tokens_from_text(sentence)
bag = [0] * len(vocabulary)
for token in tokens:
for index, vocable in enumerate(vocabulary):
if token == vocable:
bag[index] = 1
return np.array(bag)
def get_tokens_from_text(text):
tokens = nltk.word_tokenize(text)
tokens = [token.lower() for token in tokens]
return tokens
if __name__ == "__main__":
main()
Kurz zusammengefasst: Als erstes wird das Vokabular mit „get_vocabulary_from_corpus“ aus dem Korpus ermittelt. Mit „get_bag_of_words“ wird dann der Satz relativ zum Vokabular in die Bag-of-Words-Darstellung gebracht. Wir schauen uns gleich an, wie das aussieht.
Ein wichtiger Teil ist der Tokenizer. Dieser zerlegt Texte in einzelne Tokens. Also meistens Wörter und Satzzeichen. Tokens werden zweimal generiert. Einmal bei der Extrahierung des Vokabulars aus dem Korpus. Und ein zweites Mal beim Zerlegen des zu kodierenden Satzes.
Das ist die Ausgabe vom obigen Program:
Vocabulary length: 62 Vocabulary: ['!' ',' '.' ';' 'ach' 'als' 'an' 'armer' 'auch' 'bemühn' 'bin' 'da' 'das' 'daß' 'der' 'die' 'doktor' 'durchaus' 'gar' 'habe' 'heiße' 'heißem' 'herab' 'herauf' 'herum' 'herz' 'ich' 'jahr' 'juristerei' 'klug' 'krumm' 'können' 'leider' 'magister' 'medizin' 'meine' 'mir' 'mit' 'nase' 'nichts' 'nun' 'philosophie' 'quer' 'schier' 'schon' 'schüler' 'sehe' 'so' 'steh' 'studiert' 'theologie' 'tor' 'und' 'verbrennen' 'wie' 'will' 'wir' 'wissen' 'zehen' 'ziehe' 'zuvor' '–'] Bag-of-words: [0 1 1 1 0 1 0 0 1 0 1 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 1 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 1 0 0 0 1]
In der letzen Zeile steht das Bag-of-Words vom zu kodierenden Satz. Jedes Wort aus dem Satz, das auch im Vokabular vorkommt ist mit einer 1 markiert. Das ging flott.
Stemming reduziert auf Wortstämme.
Ein kleines Randthema… In der Regel sucht man danach, die intern verwendeten Wortmengen so klein wie möglich zu halten. Das ist ein wichtiger Teil der Performance-Optimierung. Je kleiner die Daten ohne Verlust des eigentlichen Inhalts sind, desto schneller trainieren wir später die Neural Networks.
Gerade hatte ich schon einmal optimiert und hatte es nicht gesagt. Ich habe alle Wörter auf die Kleinschreibung reduziert. Da fallen schonmal ein paar weg. Die Semantik gefährdet das kaum. Ich gebe zu, dass diese Vorgehensweise sehr üblich ist. Es gibt aber noch mehr. Zum Beispiel die Reduzierung der einzelnen Wörter auf ihre Wortstämme. Das nennt der Linguist voll Stolz Stemming. Und auch das ist schnell programmiert:
import nltk
import numpy as np
from nltk.stem.lancaster import LancasterStemmer
from nltk.stem.snowball import GermanStemmer
stemmer = GermanStemmer()
corpus = """Habe nun, ach! Philosophie,
Juristerei und Medizin,
Und leider auch Theologie
Durchaus studiert, mit heißem Bemühn.
Da steh ich nun, ich armer Tor!
Und bin so klug als wie zuvor;
Heiße Magister, heiße Doktor gar
Und ziehe schon an die zehen Jahr
Herauf, herab und quer und krumm
Meine Schüler an der Nase herum –
Und sehe, daß wir nichts wissen können!
Das will mir schier das Herz verbrennen."""
def main():
vocabulary = get_vocabulary_from_corpus(corpus, use_stemmer=False)
print("Vocabulary length:", len(vocabulary))
print("Vocabulary:", vocabulary)
stemmed_vocabulary = get_vocabulary_from_corpus(corpus, use_stemmer=True)
print("Stemmed vocabulary length:", len(stemmed_vocabulary))
print("Stemmed vocabulary:", stemmed_vocabulary)
def get_vocabulary_from_corpus(corpus, use_stemmer):
tokens = get_tokens_from_text(corpus)
if use_stemmer is True:
tokens = [stemmer.stem(token) for token in tokens]
vocabulary = sorted(list(set(tokens)))
return np.array(vocabulary)
def get_tokens_from_text(text):
tokens = nltk.word_tokenize(text)
tokens = [token.lower() for token in tokens]
return tokens
if __name__ == "__main__":
main()
Die entsprechende Ausgabe zeigt beim genaueren Hinsehen, was Stemming macht und was es bringt:
Vocabulary length: 62 Vocabulary: ['!' ',' '.' ';' 'ach' 'als' 'an' 'armer' 'auch' 'bemühn' 'bin' 'da' 'das' 'daß' 'der' 'die' 'doktor' 'durchaus' 'gar' 'habe' 'heiße' 'heißem' 'herab' 'herauf' 'herum' 'herz' 'ich' 'jahr' 'juristerei' 'klug' 'krumm' 'können' 'leider' 'magister' 'medizin' 'meine' 'mir' 'mit' 'nase' 'nichts' 'nun' 'philosophie' 'quer' 'schier' 'schon' 'schüler' 'sehe' 'so' 'steh' 'studiert' 'theologie' 'tor' 'und' 'verbrennen' 'wie' 'will' 'wir' 'wissen' 'zehen' 'ziehe' 'zuvor' '–'] Stemmed vocabulary length: 61 Stemmed vocabulary: ['!' ',' '.' ';' 'ach' 'als' 'an' 'arm' 'auch' 'bemuhn' 'bin' 'da' 'das' 'dass' 'der' 'die' 'doktor' 'durchaus' 'gar' 'hab' 'heiss' 'herab' 'herauf' 'herum' 'herz' 'ich' 'jahr' 'juristerei' 'klug' 'konn' 'krumm' 'leid' 'magist' 'medizin' 'mein' 'mir' 'mit' 'nas' 'nicht' 'nun' 'philosophi' 'quer' 'schier' 'schon' 'schul' 'seh' 'so' 'steh' 'studiert' 'theologi' 'tor' 'und' 'verbrenn' 'wie' 'will' 'wir' 'wiss' 'zeh' 'zieh' 'zuvor' '–']
Na gut. Hier haben wir genau ein Wort eingespart. Bei größeren Korpora wären die Einsparungen noch massiver.
Nun wissen wir was Bag-of-Words sind und wie wir die so klein wie möglich halten können. Gehen wir nun ans Eingemachte. Wie sieht das mit Deep Learning aus? Wie erschafft man auf der Basis des Bag-of-Words-Ansatzes einen Conversational Agent?
Wie funktioniert der Chatbot aus dem Magazin?
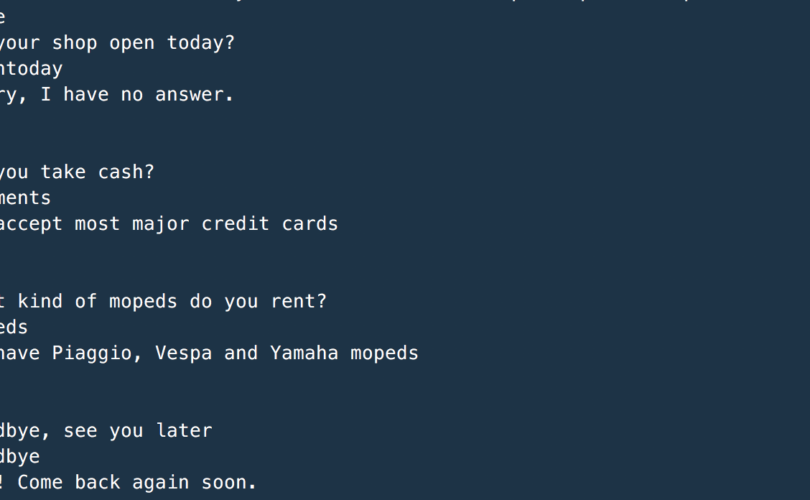
Der Artikel aus dem Chatbots Magazine hat einen einfachen Bot zum Inhalt. Dieser nimmt beliebige Anfragen und liefert dazu feste Antwortblöcke. Hier müssen wir aufpassen. Denn hier liegt eine Grenze dieser AI: Es können keine ganz neuen Antworten ohne ein erneutes Training generiert werden. Der Bot hat eine sehr eng umschriebene Domäne.
Die intellektuelle Basis des Chatbots ist eine Spezifikations-Datei. Dort sind solche Blöcke hinterlegt:
...
{
"tag": "opentoday",
"patterns": ["Are you open today?", "When do you open today?", "What are your hours today?"],
"responses": ["We're open every day from 9am-9pm", "Our hours are 9am-9pm every day"]
},
...
Diese Struktur ist leicht erklärt. „patterns“ beinhaltet als Array die möglichen Anfragen. „tag“ ordnet diese in Klassen ein. Und „responses“ sind die möglichen Antworten. Im Deep Learning sind hier diese Patterns und die Tags die Trainingsmenge. Wie sieht diese aus? Die Patterns werden mit der Bag-of-Words-Methode in 0-1-Folgen übersetzt. Die Tags werden in One-Hot-Vectors abgebildet. Hier ist ein Beispiel:
"Are you open today?" -> "opentoday" 000001000000000000000000000000010000000010000001 -> 000010000 "When do you open today?" -> "opentoday" 000000000000100000000000000000010000000010010001 -> 000010000
Links vom Pfeil steht ein Bag-of-Words, rechts als One-Hot-Vector kodiert der Index der entsprechenden Antwort-Kategorie. So sieht die ganze Trainingsmenge aus. Sie besteht aus solchen Paaren.
Deep Learning und Conversational Agents… Manchmal schießt man mit Kanonen auf Spatzen.
Zugegebenermaßen ist die Trainingsmenge hier derart klein, dass Deep Learning seine eigentliche Kraft nicht voll entfalten kann. Deep Learning ist besonders gut einzusetzen, wenn viele Daten vorliegen. Für kleine Datenmengen – wie im Beispiel – würde eine einfache Regression aus dem Machine-Learning-Werkzeugkasten bereits seinen Sinn und Zweck erfüllen. Neural Networks sind aber so gut im Verallgemeinern, dass sie auch das wunderbar hinbekommen. Deswegen will ich hier nicht böse sein. Jetzt ein Neural Network einzusetzen, würde eine spätere Erweiterung viel einfacher machen. Ich mag eine solche Voraussicht.
Steigen wir aber nun tiefer in das Thema Deep Learning ein. Ich war so frei und habe den Chatbot von TFLearn nach Keras portiert. Keras ist Stand heute ein fester Teil von Googles TensorFlow. Und ich mag Keras, weil die Modellierung und das Training von Neural Networks sehr elegant und sehr schön von der Hand geht. So der Deep-Learning-Anteil vom Chatbot in Quelltext aus:
# Model architecture. model = Sequential() model.add(Dense(input_length, input_shape=(input_length,))) model.add(Dense(8)) model.add(Dense(8)) model.add(Dense(num_classes, activation="softmax")) # For a mean squared error regression problem. model.compile(optimizer='rmsprop', loss='mse') # Training. model.fit(train_x, train_y, epochs=num_epochs, batch_size=batch_size, callbacks=[tensorBoard])
Das Neural Network ist ein einfaches Modell mit vier Schichten. Diese sind dense, also dicht, das heißt vollständig verbunden. Die „input_length“ ist die Länge der Bag-of-Words. Das ist hier die Größe vom Vokabular. „num_classes“ steht für die Anzahl an Tags in der Spezifikation des Chatbots.
Der Optimizer ist hier RMSProp. Das ist Root Mean Square Propagation, ein stochastisches Gradientenabstiegsverfahren. Dieser Optimizer sorgt hier für die Regression.
Das Training ist überschaubar. „train_x“ sind die Bag-of-Words für die Eingabe-Patterns. „train_y“ sind die One-Hot-Vectors für die Tag-Klassen. Das sind die vorhin beschriebenen Trainingspaare. Der Rest sind gängige Trainingsparameter.
Zusammenfassung
Danke fürs Durchstehen! Zugegebenermaßen habe ich recht viel geschrieben. Das Thema war es meiner Meinung nach Wert.
Der Chatbot aus dem ChatbotsMagazine ist verdammt elegant in seiner Einfachheit. Man nimmt ein paar übliche Kundenanfragen, sortiert diese in Klassen und nimmt ein paar Standardantworten dazu. Das ist das Korpus. Danach bügelt man mit der Bag-of-Words-Methode über die Eingaben und erstellt die Trainingsmenge. Ein einfacher Neuronal Network trainiert dann und macht eine Regression. Nach ein paar Minuten ist das Gehirn fertig und kann eingesetzt werden.
Der Chatbot ist aber auch begrenzt. Die Bag-of-Words-Methode skaliert nicht. Wenn das Korpus irgendwann zu groß wird, werden die Vektoren zu lang. Zu lange Vektoren gehen auf die Performance. Und leider geht bei der Methode die Semantik verloren. Eigentlich erkennt das Neural Network nur Signalworte in den Benutzereingaben und reagiert drauf.
Für mich bleibt dieser Artikel sehr wichtig, weil er eines deutlich macht: Keine Angst vor Deep Learning. Das kann heute jeder, der sich traut.





