Namaste! In one of my recent blog articles I said: Artificial Intelligence is more than just Machine Learning. I mentioned a few algorithms that are not in the ML region. Like search algorithms for problem-solving, symbolic or logic-based AI, Fuzzy Logic, classical planning, and Genetic Algorithms. Genetic Algorithms (GA) or Evolution Strategies (ES) is what I will focus on now.
School of AI Würzburg Meetup at Mayflower GmbH.
Just recently I held a School of AI meetup in Würzburg. Kindly co-organized by the overall nice guys from Mayflower GmbH. I am very grateful. Usually, we talk a lot about Deep Learning. But it is sometimes a good thing to move away from Machine Learning. Artificial Intelligence is such a huge area. And Machine Learning is just a small but very successful subfield. Thus I decided to have a look at Genetic Algorithms.
A little Charles Darwin here and there.
According to all-knowing Wikipedia, Genetic Algorithms are metaheuristics. A heuristics that find heuristics to find solutions of optimization problems. Scientifically, GAs are located in Computer Science and Operations Research. One thing that I really like about the Wikipedia article is this quote, which is GAs in a nutshell:
Genetic algorithms are commonly used to generate high-quality solutions to optimization and search problems by relying on bio-inspired operators such as mutation, crossover, and selection.

GAs were introduced in 1960 by John Henry Holland, who was a Professor of Psychology, Electrical Engineering, and Computer Science. He explicitly based his ideas on Darwin’s theory of evolution. It is time for you to read Darwins Origin of Species if you have not done so, recently 😉
Did you know...
That you can book me for trainings?That I could be your mentor?
Feel free to get in touch anytime.
Genetic Algorithms in the pseudocode nutshell.
How do GAs work? How does the overall, general algorithm look like? Please consider this pseudocode:
- Create an initial, random population of individuals of a target size.
- Compute the fitness of the whole population.
- Randomly select two individuals from the population. Using fitness as a probability distribution.
- Apply crossover and mutation to get a new individual.
- Repeat selection, crossover, and mutation until the population has the target size.
- Stop algorithm if overall fitness has converged. If not start over at the random selection step.
Very important is the fact that the individuals are represented by some data-structure. In biology this data structure is DNA. In Computer Science this could be something completely different. This data structure is called genetic representation. Something we can operate on algorithmically. We also need a fitness function, which allows us to find out how fit an individual and/or the population is. A crossover function is a routine that allows us to combine two individuals to create a new one. And a mutation function contains instructions for randomly changing the genetic representation of an individual. Finally, we need some means to determine when to stop fitting.
Everything that is promising comes with some problems.
In my world, the word „problem“ always translates to „challenge“. It is a good thing because it can be overcome. And you might learn a bit. GAs have a couple of challenges:
- Computing the fitness function might be expensive.
- Upscaling is difficult because the algorithms are very high in complexity.
- Finding a stop-criterion might be difficult.
- As in Deep Learning, the problem solver might end up in local optima.
- The area of applicability is limited.
Nevertheless, this is definitely not meant as a demotivator. There are quite some usecases for GAs.
Application areas?
One area for GAs is scheduling. In its essence, this is finding the best (optimal) time-table for X [sic!] in a huge pool of possible time-tables. This is quite related to the Traveling Salesmen Problem. Well, in a sense that true Theoretical Computer Scientists understand. Scheduling usually is NP-complete. This roughly translates to: Solving this problem works quite well with small problem instances, but explodes exponentially when the problems grow in size.
With scheduling in mind, your population would be… well… schedules. The fitness function is the efficiency of each schedule with respect to some objective function. Crossover and mutation are easily applied. And you would start with a random population of schedules and would then crossbreed and mutate the best specimen in order to find the best solution.

Real world examples? NASA did it! If you are interested, this is something that NASA did for their Deep Space Network programme.
Another sophisticated example.
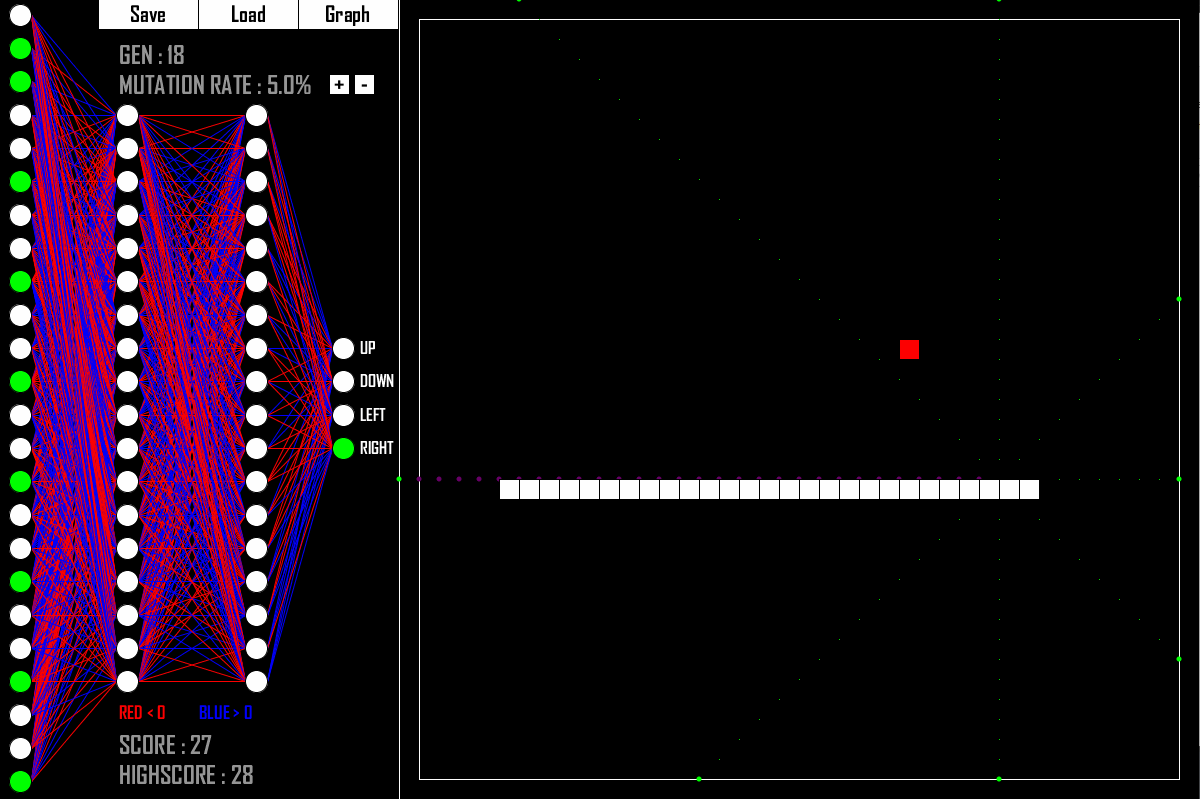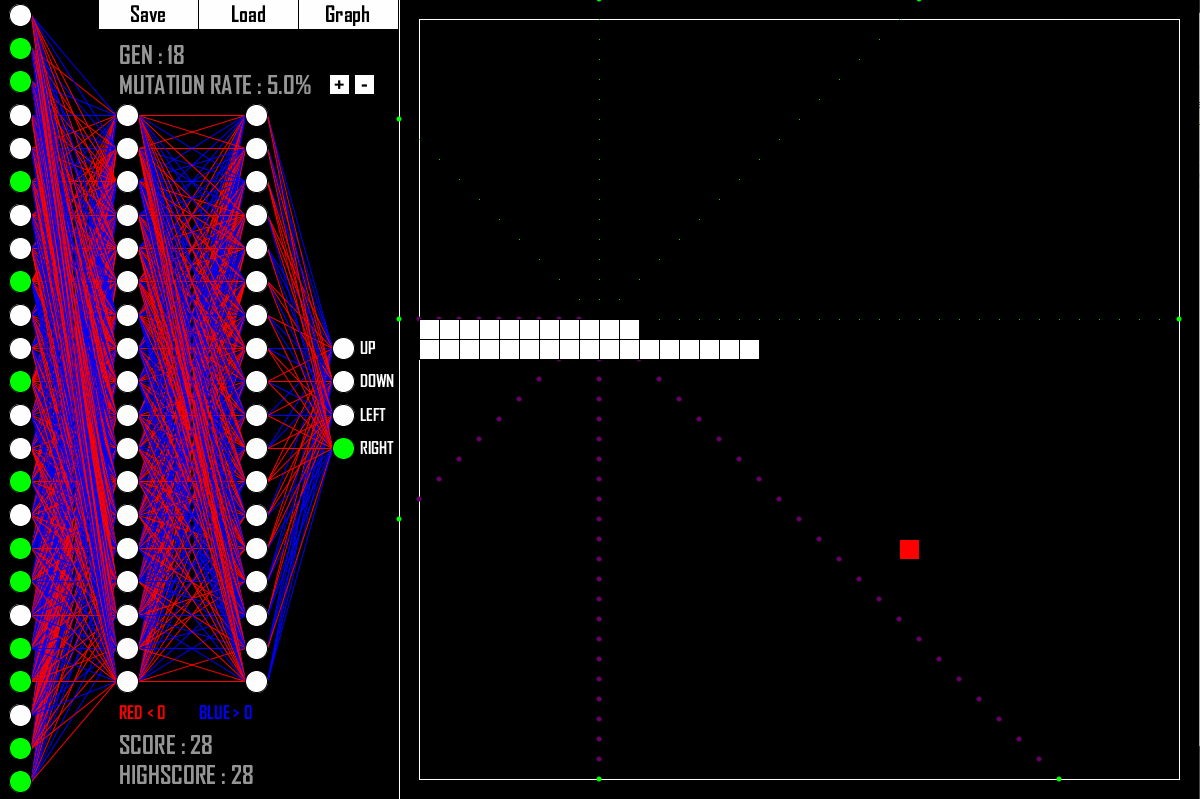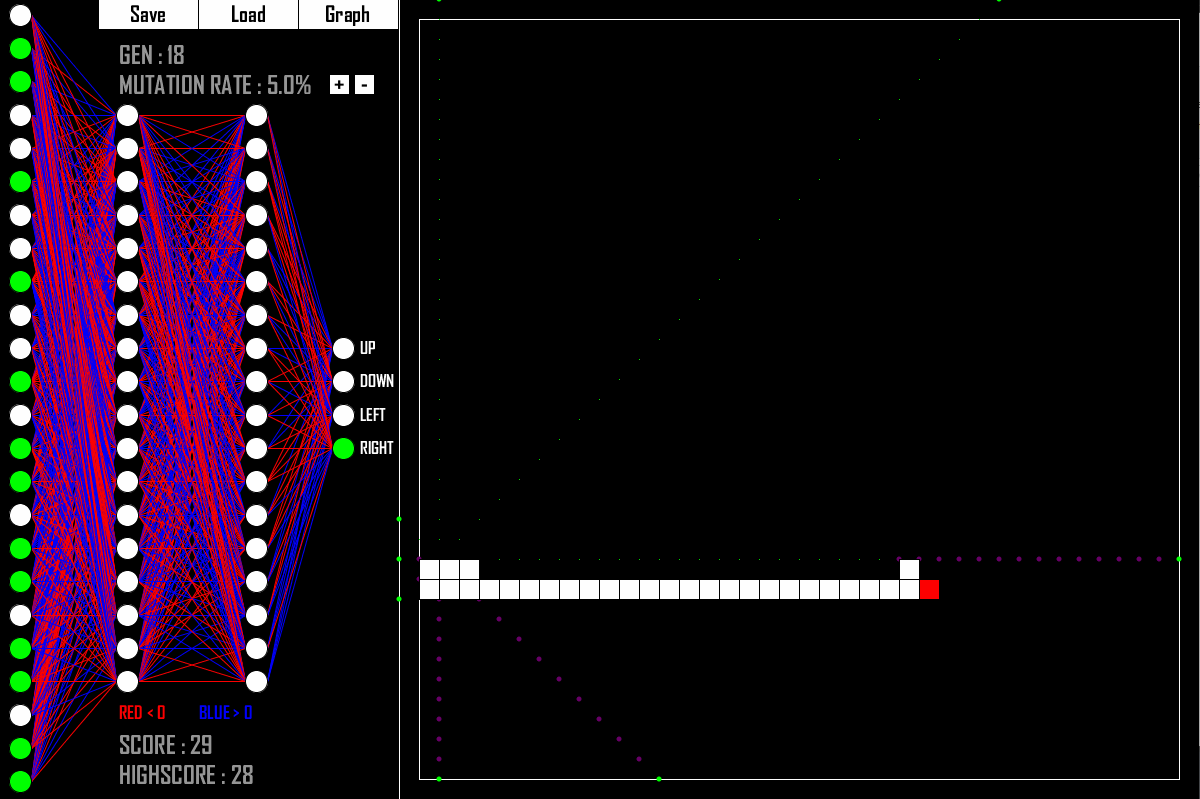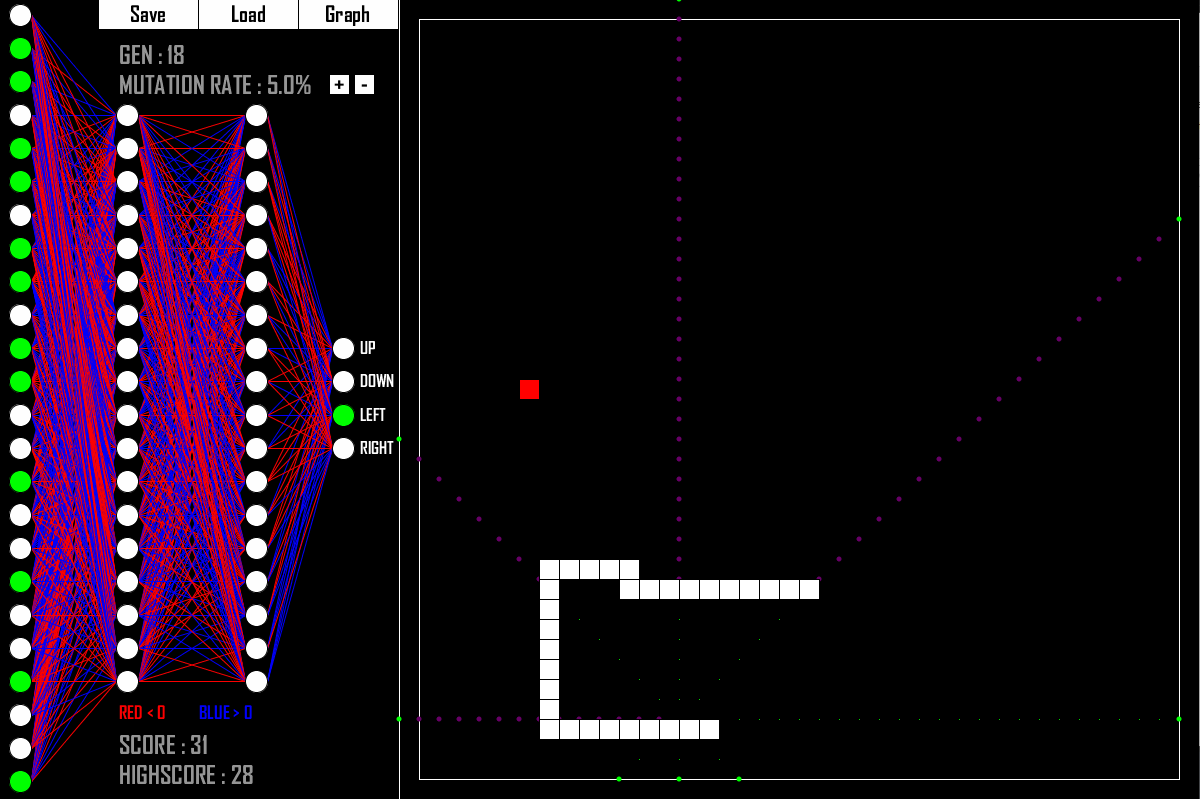
You knew I would somehow bridge the gap between Genetic Algorithms and Deep Learning. There you go! What do you see in the picture above? It is an AI that is quite good at playing the classic game Snake. And how was the AI created? Yes, with a Genetic Algorithm.
Keeping in mind our template for a generic GA as shown above, what are the core components in this case?
- Q: What is the genetic representation?
- A: The weights and biases of the Deep Neural Network. So „just“ floating point numbers.
- Q: What is the fitness function?
- A: How long a Neural Network with its given weights manages to survive the game.
- Q: What is our crossover function?
- A: Take some weights and biases from parent A and take some weights and biases from parent B.
- Q: What is our mutation function?
- A: Randomly change some weights and biases to different values.
If you want to learn more, check out Greer Viau’s SnakeAI repository.
A hint and a summary.
As you have seen, GAs are not that difficult. Instead, they follow rather simple concepts. The implementation details, however, depend on the use case at hand. Different problems require different genetic representations for individuals and different functions on how to assess the population and the creation of new generations.
You have also seen, that GAs can be used to train Deep Neural Networks. Weights and parameters are treated as genomes. There is no Stochastic Gradient Descent necessary. Uber did some research on that idea. They found out that this approach works quite well in the realm of Deep Reinforcement Learning. But this is another story… Thanks for reading!
Stay in touch.
I hope you liked the article. Why not stay in touch? You will find me at LinkedIn, XING and Facebook. Please add me if you like and feel free to like, comment and share my humble contributions to the world of AI. Thank you!
If you want to become a part of my mission of spreading Artificial Intelligence globally, feel free to become one of my Patrons. Become a Patron!
A quick about me. I am a computer scientist with a love for art, music and yoga. I am a Artificial Intelligence expert with a focus on Deep Learning. As a freelancer I offer training, mentoring and prototyping. If you are interested in working with me, let me know. My email-address is tristan@ai-guru.de - I am looking forward to talking to you!